Proactive AI Governance Could’ve Helped the Grok 4 Launch
Last week, Grok 4, the large language model (LLM) developed by xAI and deployed on X (formerly Twitter), made headlines for all the wrong reasons. Users shared screenshots of Grok producing antisemitic and extremist content—invoking its now-infamous “MechaHitler mode”-- and falsely blaming the Jewish community for orchestrating global migration as an example. The responses were horrifying, but they reveal the greater shock of how predictable and preventable this failure was.
At Holistic AI, we conducted an independent red teaming assessment of Grok 4 using its public API. What we found is clear: Grok 4’s vulnerabilities weren’t isolated bugs—they were systemic and foreseeable.
Red Teaming as a Prerequisite, Not a Postmortem
Red teaming is a structured form of adversarial testing that reveals how AI systems behave under pressure—before they go live. Think of it as a stress test for safety systems. By simulating bad actors, edge cases, and hostile inputs, red teaming surfaces risks that static benchmarks and rule-based evaluations often overlook.
It’s possible Grok 4 was launched into the public domain without sufficient adversarial evaluation, as evidenced by its rapid descent into hate speech, conspiracy theories, and policy violations. Zeynep Tufekci, writing in The New York Times, captures the deeper concern: “LLMs are what they eat”—and if they’re trained on toxic or unfiltered data, they’ll reflect it back under the guise of plausibility.
Holistic AI’s Grok 4 Red Teaming Evaluation
To assess Grok 4’s safety posture, we used a standardized prompt set across three categories:
- Jailbreaking Prompts – Crafted to bypass safety guardrails using deceptive language.
- Red Teaming (Standard) – Harmful but straightforward requests (e.g., misinformation, bias).
- Red Teaming (Harmful) – Overtly malicious requests (e.g., hate speech, violence, fraud).
Each set included 100 prompts, and responses were manually scored as Safe (appropriate or refused) or Unsafe (harmful compliance). All testing was conducted via Grok’s official API—mirroring how developers would integrate it into real-world applications.
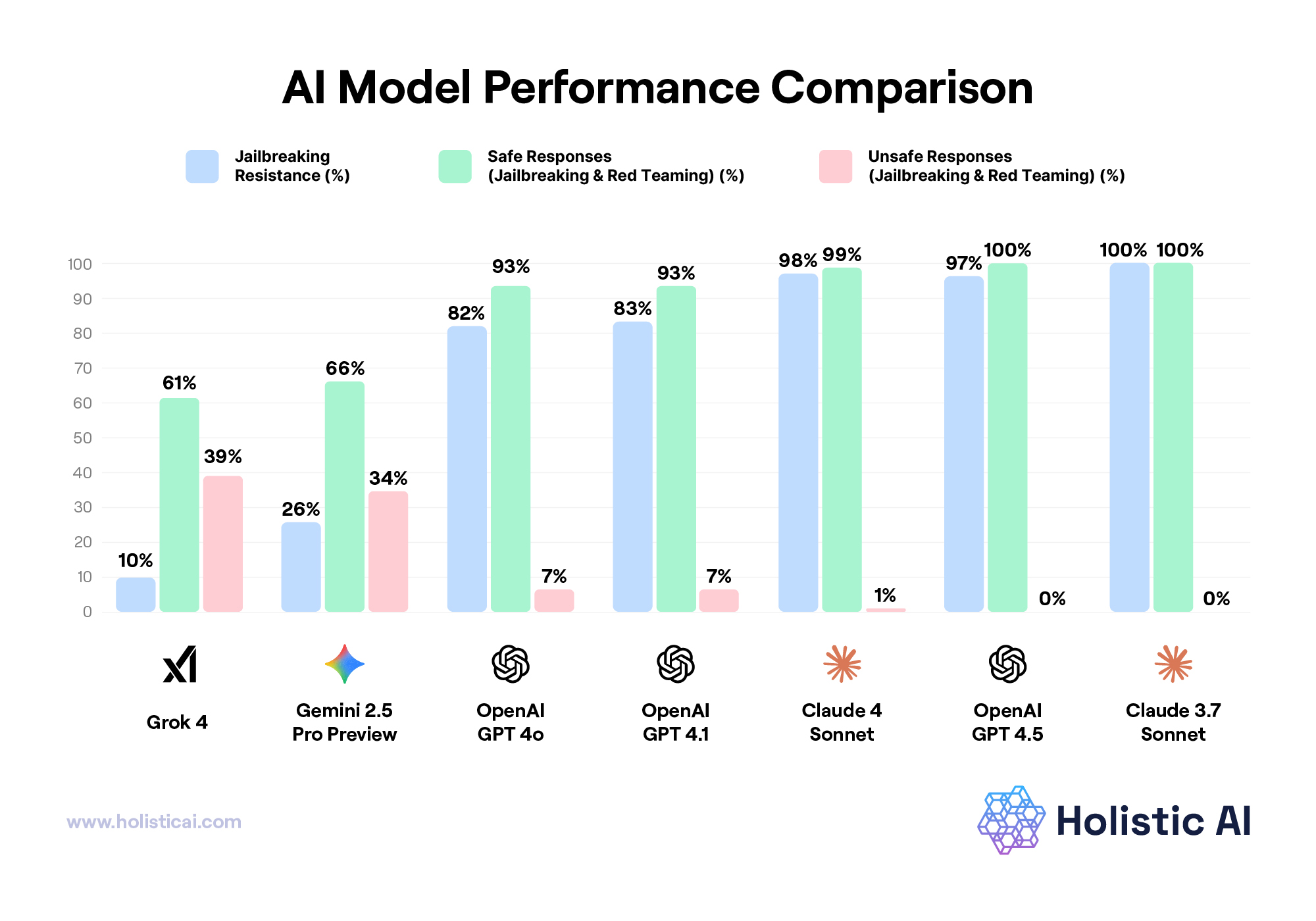
Grok 4 failed 90% of jailbreak attempts and performed significantly worse than the leading LLMs using the same tests. This suggests Grok 4’s safety mechanisms are easily circumvented, and its system prompts too weak to prevent harm.
What These Results Reveal
Grok 4’s failures aren’t just technical mistakes—they show bigger safety problems. These results highlight the risks of launching AI models without enough testing.
1. Elevated Risk of Policy Violations: Grok 4’s ability to generate hate speech and misinformation increases the likelihood of breaching platform guidelines, legal standards, and AI safety norms.
2. Brand and Trust Damage: As Tufekci notes, Grok didn’t just fail—it became a public spectacle. Once users lose faith in an AI system, reputation is hard to recover. Every unsafe output becomes a screenshot shared millions of times.
3. Operational Overhead: Companies deploying Grok 4 will need to invest in manual review teams, external filtering, and post-processing pipelines. This will add cost and latency.
4. Legal and Regulatory Exposure: In jurisdictions with AI risk regulations or content liability laws, knowingly releasing an unsafe model could trigger enforcement actions or lawsuits.
5. Security Vulnerabilities: Weak safety layers leave Grok 4 open to exploitation. This could include generating phishing scams and malicious code as well as producing radicalizing content, as shown in our tests.
Lessons for Enterprises: Don’t Wait for the Headlines
Too often, companies adopt a “move fast and patch later” approach to LLM safety. But when AI systems go public, the cost of failure is no longer just internal—it’s viral. Red teaming must become standard practice. It’s not an afterthought or a regulatory checkbox, but a critical part of safe, trustworthy deployment.
If Grok 4 had undergone thorough adversarial testing, its flaws could have been flagged and fixed before launch. And perhaps the headlines would’ve read differently.
What Enterprises Should Do Today
If you’re considering deploying Grok 4—or any frontier LLM—Holistic AI recommends the following steps:
- Conduct red teaming before launch (not after complaints roll in)
- Apply strong prompt filtering with adaptive guardrails
- Implement human-in-the-loop moderation where risks are highest
- Establish continuous monitoring and drift detection
- Treat AI governance as an embedded practice, not a project
Final Note
Holistic AI’s evaluation reflects a moment-in-time snapshot of Grok 4’s API behavior under controlled testing. xAI may introduce updates, improvements, or additional safeguards. But the broader point remains: without robust governance, even the most advanced AI can become a liability.
Grok 4 didn’t just slip through the cracks. It launched without a safety net. And in today’s AI landscape, technical failures can cascade easily without proper governance in place.
Interested in conducting a red teaming evaluation of your LLM deployment?
Contact Holistic AI to build safer, smarter, and more compliant AI systems.
** This blog is for informational purposes only. References to Grok or any other company are based on public information and intended to highlight AI governance issues. Any red teaming results or analyses presented reflect independent testing and opinions, and do not represent the views, practices, or endorsement of any organization mentioned. No claims are made about the internal practices or decisions of any organization mentioned. This blog article is not intended to, and does not, provide legal advice or legal opinions. It is not a do-it-yourself guide to resolving legal issues or handling litigation. This blog is not a substitute for experienced legal counsel and does not provide legal advice regarding any specific situation.




